

RESUMEN V.1
INTRODUCCIÓN
¿Cuántas palabras conoce una persona? cualquier hablante comprende muchas más palabras de las que emplea. Se estima que una persona con una cultura media de bachillerato conoce, en su sentido más amplio, entre 40.000 y 80.000 palabras.
| Miller y Gildea, (1987). Si un bachiller conoce 80.000 palabras y tiene 16-17 años, significa que a lo largo de su vida ha aprendido un promedio de 5.000 palabras anuales, es decir 13 diarias. |
Normalmente la palabra se considera la unidad mínima de una lengua dotada de significado. Aunque en sentido estricto, es el morfema la unidad mínima con significado. Los morfemas pueden constituir palabras por sí mismos (p. ej., «flor») o ser apéndices de otras palabras (p. ej., la s de «perros», la 2ª a de «arquitecta»). Los primeros son los morfemas libres, mientras que los segundos se conocen como morfemas ligados. Estos últimos modifican el significado del resto de la palabra y pueden ir delante (prefijos) o detrás (sufijos) de la raíz o lexema. Lexema es el morfema o parte de la palabra que tiene significado autónomo e independiente.
Los morfemas derivativos crean, por derivación, nuevas palabras, ya que modifican sensiblemente al lexema y cambian por completo su significado dando origen a otra palabra distinta. P. ej., el prefijo descambia «burro» por «burrada», «justicia» por «injusticia», que tienen significados contrarios. Aquí los lingüistas hablan de palabras primitivas, que sirven de base y palabras derivadas que se han originado a partir de las primitivas. Los morfemas flexivos, por el contrario, no alteran el significado de la raíz o lexema. Permiten la flexión de las palabras al codificar el número, el género o el tiempo verbal. P. ej., «corrupta», «corruptas», «democrata», «democratas» no son palabras completamente diferentes con significados distintos.
Al evocar una palabra en nuestra mente, activamos un amplio conjunto de información. Por supuesto, activamos su significado, aunque éste puede variar notablemente en cuanto a su precisión. Además del significado, al evocar una palabra activamos información fonológica o el conjunto de sonidos que componen dicha palabra. También activamos información ortográfica, desde el momento en que sabemos escribirla; es decir, dibujar los grafemas o letras que la representan en el lenguaje escrito. Por otra parte, sabemos que «perra» es un nombre femenino singular, «blando» es un adjetivo, «dormir» es un verbo, etc. Asimismo, sabemos qué funciones puede desempeñar cada palabra dentro de la oración. Estas dos clases de información, morfológica y sintáctica, corresponden a un conocimiento implícito que uno tiene como hablante de una lengua, con independencia de que se haya estudiado o no en la escuela. Si se tienen conocimientos de gramática podrá hacerse explícito y ser capaz de nombrar que esto es del género masculino y aquello del número plural; pero, aunque jamás se haya pisado un colegio, se dispone de esa información morfosintáctica de modo implícito y puede manejarse apropiadamente todos los días, a todas horas, al hablar y oír lenguaje.
La activación de palabras en nuestra mente se produce no sólo en el uso del lenguaje hablado, sino también en el escrito, al leer y escribir. Las principales diferencias se derivarían de la naturaleza física del estímulo y sus consecuencias perceptivas, pero nada hace pensar que los procesos centrales de comprensión sean sustancialmente diferentes en ambas modalidades. La distinción más importante es que la señal del habla se distribuye en el tiempo y es evanescente, mientras que en la escritura se distribuye en el espacio y es permanente. Además, como se ha señalado al tratar la percepción del habla, el lenguaje oral es mucho más variable que el escrito y no presenta límites claros entre sus componentes.
ESTRUCTURA Y ORGANIZACIÓN DEL LÉXICO
| R.C. Olfield (1966). Una construcción teórica útil como fuente de hipótesis (DICCIONARIO MENTAL o LEXICÓN). |
| Drenowski y Healy (1977). La probabilidad de omisión es mucho mayor cuando la letra forma parte de una palabra de función que de contenido. |
| Bradley y Garrett (1980). La frecuencia de uso es una variable que tiene un poderoso efecto en la identificación de las palabras, pero esto sucede sólo con las de contenido; parece que las palabras de función no se ven afectadas por la frecuencia léxica en la misma medida. |
| Miller (1984). Los recuentos del inglés escrito indican que la palabra más usada es ‘the’ (el, la los, las), a la que siguen ‘of’ (de), ‘and’ (y) y otras palabras de función. |
| Aitchison (1992). Las palabras de función son el cemento del lenguaje que mantiene unidos a los ladrillos formados por las palabras de contenido. Desempeñan un papel clave en la construcción de la estructura sintáctica y transmiten información esencial para la asignación de funciones dentro de la oración. |
Todas las lenguas del mundo disponen de vocabularios formados por miles de palabras. La edición 23ª del DRAE recoge 93.111 lemas o entradas, y se sirvió del Banco de Datos del Castellano, que cuenta con más de 270 millones de registros acumulados a través de los años. A pesar de la diversidad, los vocabularios de las distintas lenguas se ajustan a unos principios generales que se describen a continuación.
Dos vocabularios básicos
Es posible distinguir entre dos clases de palabras muy diferentes que, según indican los datos, se procesan de forma distinta en el cerebro humano. Desde el punto de vista lingüístico:
Categorías mayores o de clase abierta, son los ladrillos del habla (nombres, verbos, adjetivos y algunos adverbios). Las palabras de clase abierta, o palabras de contenido, poseen significado pleno y son, con diferencia, el grupo mayoritario, formado por decenas de miles de vocablos. Se denominan de clase abierta porque constituyen un conjunto que no cesa de incorporar nuevos términos a lo largo del tiempo. Son palabras que surgen y se usan en la calle y que luego, normativamente, pasan a formar parte del idioma. En el español, es la Real Academia Española quien se encarga de esa tarea a través del DRAE, cuyas sucesivas ediciones suman miles de nuevos vocablos, todos ellos de clase abierta.
Categorías menores o de clase cerrada, el cemento que une los ladrillos (artículos, preposiciones, conjunciones, auxiliares, etc.). La clase cerrada, o palabras de función (también denominadas functores), se componen de elementos sin contenido semántico pleno, que sirven para modificar el significado de las otras palabras y establecer relaciones entre ellas. No es lo mismo «ir a Valencia» que «ir desde Valencia», «estar en la caja» que «estar sobre la caja», etc. En castellano la palabra más frecuente es «de», según la base LEXESP, y le siguen «la», «que», «y», «el», «en», etc., todas ellas palabras de función.
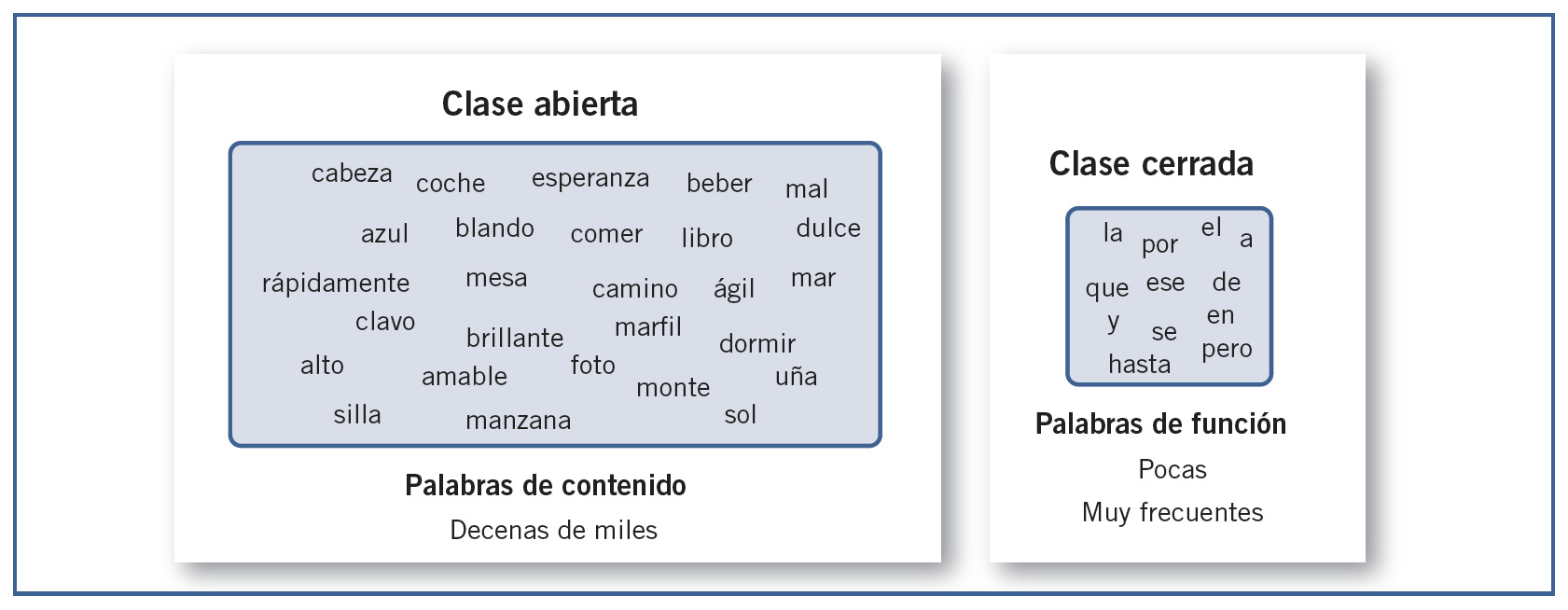
Hay evidencias de que la representación y el procesamiento de ambos tipos de vocabulario presentan importantes diferencias.
Lesiones cerebrales
Una lesión puede afectar selectivamente más a un tipo de vocabulario que al otro. En la afasia de Broca hay mayor dificultad para el uso de las palabras de función (vocabulario de clase abierta) que de las de contenido. En la afasia de Wernicke, cuyos pacientes no entienden ni producen las palabras de contenido, estos pacientes tienen graves dificultades para comprender el lenguaje, se derivan principalmente del deterioro en el procesamiento de palabras de contenido (vocabulario de clase cerrada).
Adquisición del lenguaje
Se sabe que la aparición del vocabulario de clase cerrada (palabras de contenido) es mucho más tardía que la del vocabulario de clase abierta (palabras de función). Las primeras palabras infantiles son fundamentalmente de clase abierta (o de contenido).
Resultados experimentales y observacionales
Experimentos con adultos sanos arrojan resultados distintos con unas y otras palabras. La frecuencia de uso es una variable que tiene un poderoso efecto en la identificación de las palabras, pero esto sucede sólo con las de contenido; parece que las palabras de función no se ven afectadas por la frecuencia léxica en la misma medida (Bradley y Garrett, 1980). Hay trabajos que ponen de manifiesto una mayor «invisibilidad» de las palabras de función, en tareas que consisten en identificar rápidamente una letra particular sobre un texto.
Organización del léxico mental
| Taft y Forster (1975). Según la Hipótesis del listado parcial o segmentación obligatoria, para identificar una palabra morfológicamente compleja, primero debemos «despojarla» de todos sus afijos y luego localizar su forma base. |
| Taft (1981). El hecho de que los tiempos de reacción de palabras seudoprefijadas como «interés» o «resultado» que realmente no tienen prefijos pero tienen apariencia de tenerlos (in- y re-, respectivamente), se procesan más lentamente que las palabras control, parece apoyar la hipótesis del listado parcial. |
| Caramazza, Laudanna y Romani (1988). Lo que realmente apoyan los datos empíricos de forma clara es la hipótesis mixta o dual. |
| Emmorey y Fromkin (1988). Una distinción que se ha revelado útil es aquella que discierne entre una morfología de nivel I, en la que se produce una alteración de la raíz (de «soñar», «sueño»; de «toro», «taurino»), y una morfología de nivel II, donde no se altera la raíz (de «comer», «co-medor»; de «misa», «misal»). |
| Belinchón et al. (1992). Comprender una palabra implica comparar y acoplar un estímulo externo (escrito o hablado) con estructuras de información previamente representadas en la memoria del oyente. |
| Belinchón et al. (1992). Al igual que un diccionario tiene entradas que corresponden a las distintas palabras incluidas, el léxico mental constaría de una lista o red de «entradas léxicas», cada una de la cuales incorporaría, al menos, la siguiente información |
| Marslen-Wilson et al. (1994). Parece que un factor que influye en la descomposición de las palabras es el grado de transparencia que éstas tienen para nosotros. |
| Altman (1997). Una forma de pensar sobre esto [el acceso léxico] es recordar que, en último término, toda la información del léxico mental está almacenada dentro de estructuras neurales del cerebro. |
| Cuetos (2003). El fenómeno de la «punta de la lengua» es un fenómeno normal que ocurre de forma esporádica; sin embargo, algunas lesiones cerebrales pueden dar lugar a un cuadro de anomia, en el que el enfermo tiene gran dificultad para recordar el nombre de las palabras, incluso de las más comunes. |
¿Cuánto tiempo transcurre desde que escuchamos la palabra «mosca» y evocamos mentalmente el insecto? Parece que la comprensión es un estado mental que brota de forma repentina en nuestra conciencia, sin ningún paso intermedio. Sin embargo, hoy sabemos que esta «atemporalidad» es sólo aparente; la compresión es, en realidad, la culminación de un conjunto complejo de subprocesos que ocurren de forma rápida y automatizada, y de los cuales no somos conscientes, ni podemos observarlos introspectivamente. Sólo somos conscientes del resultado final.
¿cómo y dónde guardamos en nuestra cabeza toda la información de que disponemos sobre miles de palabras de nuestro idioma? ¿Cómo está organizado nuestro hipotético «léxico mental» en el cerebro? Olfield (1966) propone el concepto de diccionario o léxico mental, como la hipotética estructura donde se representaría esta información de manera organizada. Se trata de una fuente de hipótesis que se pueden verificar empíricamente con experimentos psicolingüísticos. Su materialización neural la irá desvelando el avance de la neuropsicología (estudio de las lesiones y sus efectos) y de las neurociencias.
Según Belinchón et al., el léxico mental constaría de una lista o red de «entradas léxicas»:
- Una representación fonológica, acerca de los sonidos que constituyen la palabra, cómo se pronuncia.
- Una representación ortográfica, el conjunto de letras que forman la palabra, cómo se escribe.
- Una representación morfológica, que refleja su estructura y categoría gramatical (sustantivo, verbo, adjetivo, etc.).
- Una representación sintáctica, que indica las funciones que puede representar la palabra (sujeto, objeto directo, objeto indirecto, etc.).
- Una representación semántica sobre su significado.
- Representación de red o conjuntos. Términos, o conceptos asociados a la entrada léxica por sus significados.
A veces, en el uso diario del lenguaje puede fallar la conexión entre algunas de esas representaciones, de manera que no se activen todas como sería deseable: por ejemplo, en el fenómeno de la «punta de la lengua» no somos capaces de activar la información fonológica y ortográfica de la palabra, pero sí la semántica (podemos detallar aspectos de su significado, para qué sirve el objeto designado por la palabra, etc.) e incluso morfosintáctica (si es género masculino o femenino).
¿Listado exhaustivo o listado parcial?
En ese hipotético diccionario o léxico mental, palabras como «comer», «comió» y «comedor» ¿tienen una entrada léxica cada una, o sólo existe una única entrada a partir de la cual se derivan todas las variantes morfológicas? Como tantas en la psicolingüística, es una cuestión abierta,, sin una respuesta única. Existen al respecto dos hipótesis alternativas:
- Hipótesis del listado exhaustivo. Considera que cada variante tiene su entrada o representación propia.
- Hipótesis del listado parcial o segmentación obligatoria. Defiende que el léxico sólo contiene una lista parcial de entradas léxicas que incluye, por un lado las raíces o «formas base», y por otro los afijos (prefijos y sufijos). Para identificar una palabra morfológicamente compleja, primero debemos «despojarla» de todos sus afijos y luego localizar su forma base. Bastantes datos empíricos parecen apoyar esta segunda hipótesis.
Los datos empiricos apoyan claramente una tercera hipótesis, la hipótesis mixta o dual. Por una parte existe un listado exhaustivo para las palabras irregulares, para las monomorfémicas y para las muy familiares aunque sean regulares, ya que por su gran uso puede resultar más operativo mantener representaciones independientes de todas sus formas, y, por otra parte, estarían las palabras morfológicamente complejas y regulares de manera segmentada, ya que por un lado se encontrarían las raíces y por otro lado los afijos. Ambas partes se procesan por separado y posteriormente se unen. Este procedimiento es especialmente útil con las palabras de baja frecuencia, pues no es necesario conocer todas las formas derivadas para entender y utilizar una forma concreta (no es necesario disponer de todas las formas del verbo «bracear» para entender la palabra «braceábamos»).
En realidad, la noción de morfema es complicada y, desde el punto de vista psicológico, puede responder a realidades distintas. Si una palabra compuesta no es transparente respecto a sus componentes se representará como otra palabra aparte; por ejemplo, «camaleón» no es transparente respecto a sus componentes «cama» y «león» y se almacena independientemente de estas últimas. Paralelamente, una distinción que se ha revelado útil es aquella que discierne entre una morfología de nivel I, en la que se produce una alteración de la raíz, y una morfología de nivel II, donde no se altera la raíz. Probablemente, las transformaciones de nivel I darían lugar a unidades nuevas en el léxico mental, mientras que las de nivel II tenderían a depender de una única entrada léxica.
Acceso léxico
Muchos autores entienden que en la operación de acceder al léxico mental desempeña un papel especial la primera porción de la palabra, como se verá al tratar los modelos teóricos. Otros autores, generalmente conexionistas, consideran innecesario plantear un mecanismo de acceso separado del mecanismo de activación léxica.
En el reconocimiento de las palabras habladas, la mayor parte de los enfoques teóricos sobre el acceso léxico comparten la idea de que intervienen dos tipos de mecanismos fundamentales: activación y competición. Pese a la diversidad de modelos y aproximaciones teóricas (TRACE, Shortbst, PARSYN, DCM, etc.), hay consenso en aceptar que el input, o información de entrada, activa un conjunto de candidatos posibles que compiten entre sí en el proceso de identificación léxica.
METODOLOGÍAS EXPERIMENTALES
A las técnicas experimentales para explorar los procesos de acceso léxico o reconocimiento de palabras hay que añadir las técnicas de neuroimagen sobre la activación cerebral.
Técnica gating (apertura sucesiva)
| Francois Grosjean (1980). Autor de la versión actual de la técnica gating. |
En esta tarea, un estímulo lingüístico (habitualmente, una palabra monosílaba) se va presentando a través de sucesivos segmentos de duración creciente, hasta que puede ser identificado. Habitualmente los segmentos se inician desde el principio del estímulo. El primer segmento normalmente es muy corto (20-30 ms), y el último abarca ya el estímulo entero. La variable dependiente (VD) es la duración mínima del estímulo que permite su identificación.
Detección de estímulos (monitoring)
| Foss (1969). El primero en utilizar la técnica de detección de estímulos (monitoring) |
La tarea consiste en responder rápidamente, pulsando un botón, cada vez que aparece un estímulo determinado (fonema, sílaba, palabra, etc.) establecido previamente en las instrucciones, al mismo tiempo que procesa cierto material lingüístico, palabras, oraciones, discursos, etc. El tiempo de reacción para la detección del estímulo se considera un reflejo de la carga de trabajo que tiene el sistema cognitivo en ese momento, mientras procesa el material lingüístico. La tarea también implica una decisión.
Decisión léxica
| Rubenstein, Garfield y Millikan (1970). Los primeros en utilizar la técnica de la decisión léxica en la modalidad visual. |
| McCusker, Holley-Wilcox y Hillinger (1979). Los primeros en utilizar la técnica de la decisión léxica en la modalidad auditiva. |
Se trata de una de las tareas más usadas en la psicolingüística, tanto en la modalidad auditiva como en la visual. En la tarea visual, el participante debe decidir rápidamente si un estímulo formado por un conjunto de letras es una palabra de su idioma o no lo es. En la modalidad auditiva, el participante debe decidir si los sonidos que escucha, normalmente a través de unos auriculares, forman una palabra o no. La variable dependiente es el tiempo de reacción, generalmente analizado sólo en las palabras, es decir, los milisegundos que transcurren entre la presentación del estímulo y la respuesta del sujeto. Unos 500-700 ms son tiempos habitúales, dependiendo de cada palabra. Otra variable dependiente que también se tiene en cuenta es la proporción de errores. El participante accede y busca velozmente en su «diccionario» mental y, si encuentra una unidad léxica, responde con la tecla «sí». Si busca y «agota» el diccionario sin encontrar una unidad léxica, termina respondiendo «no»; esto generalmente consume más tiempo.
Otros métodos
| Cutler y Norris (1988). Introduce la tarea de localización de palabras (wordspotting), sobre todo en investigaciones sobre la influencia de la estructura prosódica del lenguaje (entonación y ritmo) en el reconocimiento léxico. |
En los estudios sobre el significado de las palabras se emplean tareas de decisión o categorización semántica, donde el participante debe tomar una decisión rápida, pulsando un botón, en respuesta a procesos de carácter semántico. También hay tareas de categorización sintáctica, como la decisión de género y otras. A partir de Cutler y Norris (1988), se ha introducido la tarea de localización de palabras (wordspotting), sobre todo en investigaciones sobre la influencia de la estructura prosódica del lenguaje (entonación y ritmo) en el reconocimiento léxico. Este método tiene cierta validez ecológica, en el sentido de que intenta emular el proceso natural de reconocer palabras dentro de una corriente continua de habla. En ocasiones los experimentos sobre el reconocimiento de palabras son difíciles de interpretar porque los datos no confluyen en un cuadro coherente. No hay ninguna tarea «pura» que refleje únicamente el subproceso que se pretende estudiar. En palabras de Harley (2009), es como si se usara un telescopio para juzgar el color de las estrellas y el color de sus lentes cambiará dependiendo de la distancia a la que se hallaran esas estrellas.
VARIABLES QUE INFLUYEN EN EL RECONOCIMIENTO DE LAS PALABRAS
Cualquier modelo teórico que aspire a ser una explicación coherente de los mecanismos de acceso léxico, debe ser capaz de dar cuenta de la variables que influyen en el reconocimiento de palabras.
Punto de unicidad
Uno de los efectos más determinantes del conocimiento oral de palabras es el del punto de unicidad, esto es, el punto de la palabra en el que se convierte en única del idioma, ya que no hay ninguna otra que comience por esos mismos fonemas. Cuando el oyente percibe el primer fonema, se activan en su léxico todas las palabras que comienzan por ese fonema. Por el contrario, con las palabras que tienen el punto de unicidad al final, hay que esperar a oír todos los fonemas para poder reconocerlas. Se trata, por lo tanto, de una variable determinante de los tiempos de reconocimiento de las palabras habladas: cuanto más al comienzo se encuentra el punto de unicidad, antes se reconoce la palabra.
Frecuencia léxica
| Juilland y Chang-Rodríguez (1964). Diccionario de frecuencias construido a partir de un corpus de medio millón de palabras, utilizando la tecnología del momento basada en las tarjetas perforadas. |
| Alameda y Cuetos (1995). Diccionario de frecuencias elaborado en la Universidad de Oviedo, y que abarca 2 millones de palabras. |
| Nuria Sebastián-Galles, et al. (2000). LEXESP (léxico informatizado del español), integrado por un corpus de cinco millones de palabras. |
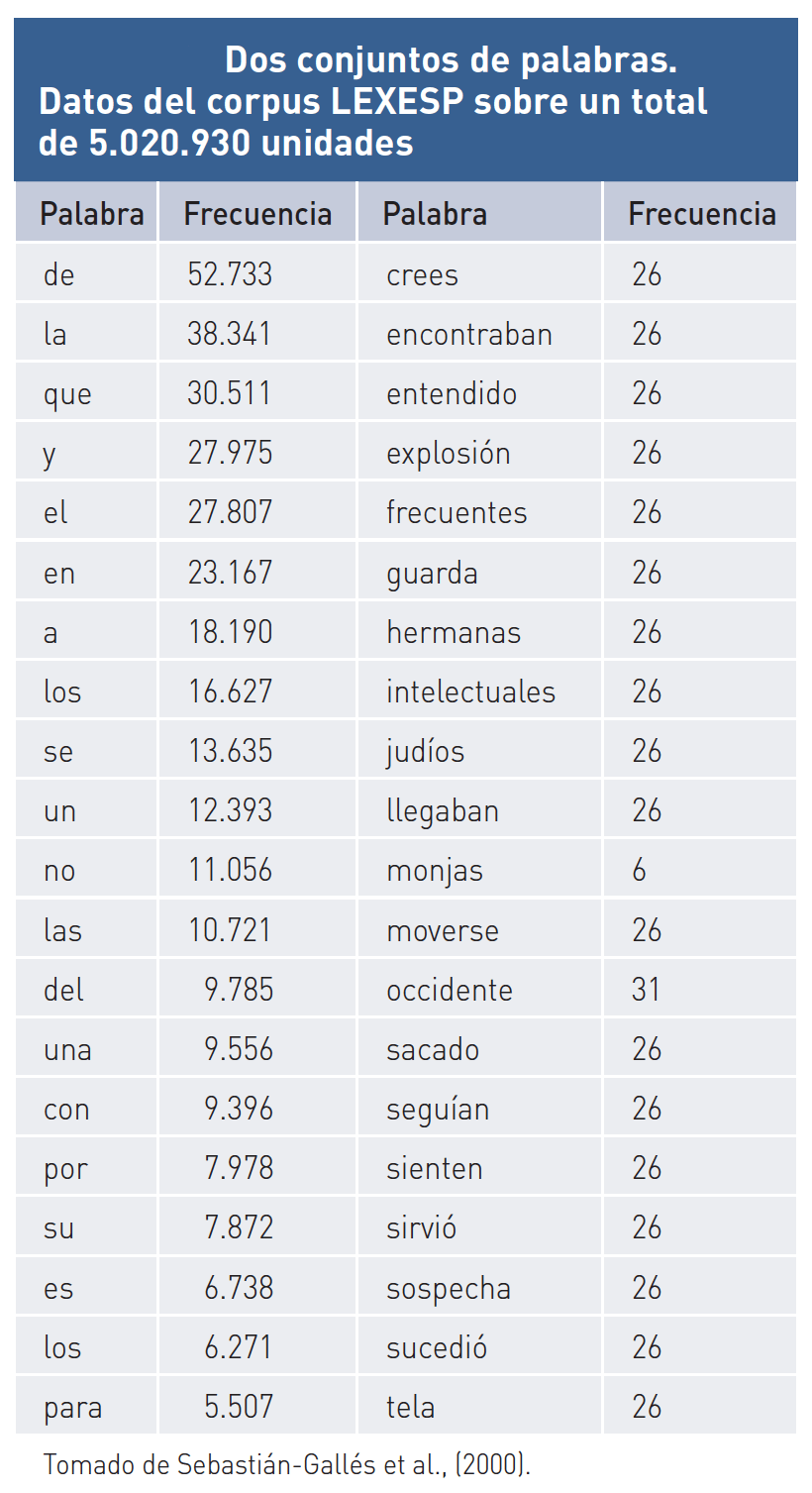
Es uno de los efectos más robustos de la psicolingüística; se replica en cualquier laboratorio del mundo con lenguas distintas y en condiciones muy diversas. Consiste en que las palabras usadas con más frecuencia en un idioma se identifican más fácilmente y con mayor rapidez que las empleadas con menos frecuencia. Debido al papel tan importante de la frecuencia léxica en el reconocimiento de palabras se han elaborado diccionarios de frecuencia en la mayoría de los idiomas para poder cuantificar de manera fiable esta variable. Estos diccionarios se construyen haciendo recuentos a partir de un corpus o un conjunto amplio de muestras naturales de lenguaje, generalmente escrito, extraídas de ámbitos muy variados (literatura, revistas, periódicos, ensayos, etc.). Los datos obtenidos en muchos idiomas arrojan un mismo patrón general: unas pocas palabras, sobre todo las de función, se usan muchísimo, mientras que otras se emplean en pocas ocasiones; entre ambos extremos se distribuye todo el conjunto. El corpus LEXESP incluye un conjunto de exactamente 5.020.930 unidades léxicas escritas, y en su construcción participaron autores de varias universidades españolas. Las palabras más frecuentes son muy cortas y casi todas son palabras de función, mientras que las otras son palabras de contenido y de mayor longitud. Las 6 palabras más frecuentes («de», «la», «que», «y», «el», «en») explican por sí solas el 20% de las palabras usadas en el lenguaje escrito.
Un problema que existe con estos diccionarios es que se han construido sobre muéstreos de textos escritos y, obviamente, el lenguaje oral y el escrito no son del todo equivalentes, por lo que podría ocurrir que estas medidas de frecuencia fuesen apropiadas para tareas de lectura pero no tanto para el lenguaje oral. La ausencia de diccionarios de frecuencia del lenguaje oral se debe a que es mucho más costoso obtener un corpus del habla que de los textos escritos. Sin embargo, en los últimos años se han construido diccionarios a partir de los subtítulos de las películas y series televisivas, ya que son fáciles de obtener de Internet y reflejan el lenguaje oral de las películas.
| Foss (1969).Uno de los primeros trabajos que pusieron al descubierto los efectos cognitivos de la frecuencia léxica. Encontró que las latencias para detectar el fonema eran claramente más cortas después de una palabra frecuente, presumiblemente porque exigía menor carga de procesamiento que una palabra poco frecuente. |
| Gernsbacher (1984). En realación con la medida de familiaridad, los resultados demuestran, sin embargo, que estas puntuaciones subjetivas guardan una estrecha relación con los índices objetivos obtenidos en los recuentos estadísticos, y el coeficiente de correlación es alto: r > 0,80. |
| Balota y Chumbley (1984). Estos autores no hallaron efecto de la frecuencia en una tarea de categorización semántica, en la que los participantes debían decidir rápidamente si una entidad determinada pertenecía a una categoría semántica previamente fijada (p. ej., ante la categoría prefijada «ave» emitir una decisión rápida sobre estímulos como «gallina», «león», «pingüino» «mosca», «gorrión», etc.). |
| Balota y Chumbley (1984). Interpretaron que el efecto de la frecuencia encontrado en otros estudios, sobre todo en los basados en la tarea de decisión léxica, que es donde se observa de forma más notoria, era debido a las peculiaridades de la propia tarea, concretamente, al propio proceso de «toma de decisión». Estos autores consideran que la frecuencia de uso no influye realmente en el acceso al léxico mental, sino en el proceso posléxico de la toma de decisión. |
| Cuetos et al. (2011). A través de los subtítulos se han elaborado diccionarios de frecuencia oral en multitud de idiomas, incluidos inglés, francés, chino, etc., y también en español sobre un corpus de 45 millones de palabras. |
En realidad, la verdadera variable psicológica es la familiaridad subjetiva que las personas tienen con cada palabra, la cual está determinada por la historia biográfica particular de cada uno, y no tanto por las veces que una palabra aparece contabilizada en un diccionario de frecuencias sobre un idioma. La medida de familiaridad se obtiene en estudios normativos, en los que las personas otorgan puntuaciones a un conjunto de palabras sobre una escala de familiaridad. Los resultados demuestran, sin embargo, que estas puntuaciones subjetivas guardan una estrecha relación con los índices objetivos obtenidos en los recuentos estadísticos, y el coeficiente de correlación es alto: r > 0,80 (Gernsbacher, 1984). Por esta razón y por motivos prácticos, en los experimentos suelen emplearse los índices objetivos de los diccionarios de frecuencias.
La cuestión del lugar de esta variable es todavía un debate abierto. Muchos autores defienden que la frecuencia léxica tiene una influencia real y automática en el reconocimiento de las palabras, y que surge en tareas que no requieren ningún tipo de decisión. Por otra parte, el efecto de la frecuencia léxica podría quedar subsumido u oscurecido en las tareas de categorización semántica, en las que los tiempos son mucho más largos e influyen poderosamente otras variables, en particular la tipicidad de cada ejemplar dentro de una categoría. Por ejemplo, un gorrión o una gallina son ejemplares más típicos de «ave» que un pingüino, y esta variable ejerce una fuerte influencia en los tiempos de reacción. Sin embargo, es difícil aislar el efecto de esta variable del de otras con las que normalmente guarda relación en el vocabulario de un idioma. La variable frecuencia léxica tiende a relacionarse con otras variables, como el grado de concreción, el número de significados, la longitud de la palabra, etc., que también afectan a los procesos léxicos.
Edad de adquisición
La edad de adquisición se refiere la edad a la que se aprende cada palabra a lo largo de la vida. Algunas palabras ya son conocidas por los niños durante los primeros años de su vida, otras las aprenden cuando empiezan la escolaridad y otras no las aprenden hasta edades bastante tardías. Numerosos experimentos han mostrado que la edad de adquisición es una variable muy determinante del reconocimiento de las palabras, con independencia de la metodología que se utilice, hasta el punto que algunos autores sostienen que es incluso más importante que la frecuencia de uso, puesto que muchos de los efectos que se habían atribuido a la frecuencia en realidad corresponden a la edad de adquisición.
Un problema de la variable edad de adquisición es que es más difícil de cuantificar que la frecuencia. Si para la frecuencia basta con tomar un buen número de textos y, con un programa informático, contar las veces que aparece cada palabra, con la edad de adquisición la tarea de saber en qué momento aprenden por lo general los niños cada palabra es realmente complicado. En algunos casos se hacen análisis de los registros del habla de los niños, pero el problema es que éstos no utilizan todas las palabras que conocen. Otras veces se pregunta a los padres o profesores sobre las palabras que creen que sus hijos o alumnos conocen. La medida objetiva más aceptada fue la utilizada por Morrison, Chappell y Ellis, consistente en presentar dibujos de objetos a niños de diferentes edades para que los nombraran. Este procedimiento es objetivo pero ciertamente muy arduo cuando se quiere obtener una amplia base de datos sobre la edad de adquisición. Por otra parte, con este procedimiento no se pueden recoger datos para las palabras abstractas que son imposibles de representar mediante fotografías o dibujos. Por esa razón, las medidas más utilizadas son las denominadas escalas subjetivas de edad de adquisición. Estas se obtienen presentando una lista de palabras a adultos para que puntúen sobre una escala (generalmente de 1 a 7) la edad a la que creen que aprendieron cada palabra. El 1 significa antes de los 2 años de edad, el 2 entre 3 y 4 años, etc. Aunque parezca una medida muy subjetiva, los valores que se obtienen con este procedimiento guardan una correlación muy alta con los obtenidos presentando dibujos a los niños, por lo que es la más utilizada por los investigadores.
| Izura y Ellis (2002). Se plantean si el verdadero efecto de esta variable es la edad de adquisición per se o es, en realidad, el orden de adquisición que siguen unas palabras respecto a otras. |
Lexicalidad
En la tarea de decisión léxica, el tiempo nefario para decidir que un estímulo es una palabra suele ser, en general, más corto que el que se requiere para decidir que no es una palabra. De alguna manera, el participante «agota» su diccionario o léxico mental sin encontrar una unidad léxica que se acople con el estímulo y responde con el botón «no». Esta operación consume más tiempo que la localización de una unidad léxica y que la respuesta «sí». Pero esto ocurre siempre que se cumpla una condición: que los estímulos no-palabras se ajusten a las normas ortográficas y fonológicas del idioma. Cuando esto no se cumple, los tiempos de rechazo son muy cortos porque el sujeto, probablemente, ni siquiera intenta acceder a su léxico mental. Así, la secuencia «xghytz» es inmediatamente rechazada como no-palabra, sin ningún intento de búsqueda léxica. Por otra parte, las seudopalabras tardan más en ser rechazadas cuanto más se parecen a alguna palabra existente (Coltheart et al., 1977) o incluyen una palabra en su interior (p. ej., «camaler» incluye la palabra «cama», Sánchez-Casas y García-Albea, 1984).
Vecindad fonológica
Se consideran vecinos fonológicos de una palabra todas aquellas que comparten todos los fonemas, excepto uno, y en las mismas posiciones. Hay palabras con muchos vecinos, podría decirse que habitan en vecindarios muy densos o populosos; por ejemplo, «casa» tiene como vecinos a «masa», «pasa», tasa», «gasa», «cosa», «capa», «cama», «cava», -cana», etc. En el otro extremo están las palabras ermitaños, que no tienen vecinos, como «tifus».
| Luce y Pisoni, 1998; Ziegler, Muneaux, y Graiger (2003). La mayoría de los estudios encuentran que la vecindad fonológica tienen efectos inhibitorios en el reconocimiento de palabras habladas, ya que, cuantos más vecinos tiene una palabra, más se tarda en reconocerla. |
Efecto del contexto (priming)
Sabemos que el reconocimiento de las palabras se realiza más rápidamente si van precedidas de un contexto con el que guardan relación. En los experimentos típicos de priming se presenta un punto de fijación (p. ej., un asterisco) durante 500 o 1.000 ms, después se presenta el prime durante un tiempo muy breve, en torno a los 250-500 ms y un momento después se escucha el target al que los sujetos tienen que responder. La separación entre el prime y el target suele ser un tiempo muy breve, unos pocos milisegundos, y se denomina stimulus onset asinchrony (SOA).
| Meyer y Schvaneveldt (1971). Comprobaron que las personas reconocen más rápidamente la palabra «mermelada» cuando va precedida de «mantequilla» que cuando va precedida de otra palabra no relacionada, como puede ser «enfermera». Por el contrario, la palabra «doctor» es reconocida más rápidamente precedida de «enfermera» que de «mantequilla». |
Los efectos del priming se calculan siempre comparando los tiempos de reconocimiento de la palabra target cuando va precedida del prime (mesa-silla) respecto a si va precedida de una palabra no relacionada (p. ej., coche-silla). Dichos efectos pueden ser facilitadores, si disminuyen los tiempos de reconocimiento, o inhibidores, si los aumentan. El hecho de que los efectos sean facilitadores o inhibidores depende del SOA y del tipo de relación entre prime y target. Hay que destacar que el fenómeno del priming afecta sólo a las palabras reales, no a los estímulos que son no-palabras. Así, en el priming de repetición existe una facilitación en el caso de «mesa-mesa», pero no en «nizo-nizo». Esto indica que se trata de un efecto lingüístico, y no puramente perceptivo.
Otras variables
Hay además otras variables que, aunque menos influyentes que las anteriores, también tienen efectos sobre los tiempos de reconocimiento, las más conocidas son las que vemos a continuación.
Imaginabilidad
| Paivio (1971). Las palabras concretas y altamente imaginables se recuerdan mejor que las abstractas y difícilmente imaginables en las pruebas de memoria . |
| De Groot (1989). Las palabras concretas producen mejores tiempos en la tarea de decisión léxica, sobre todo en las palabras de baja frecuencia léxica. |
Se refiere a la facilidad con que uno puede imaginar el significado de una palabra. Hay palabras fáciles de imaginar, como «nazi», «gato» o «libro», y otras en la que es muy difícil producir una imagen, como «verdad», «ética» o «libertad». En experimentos de priming, las palabras concretas facilitan mejor a las concretas, y las abstractas a las abstractas. Al igual que la edad de adquisición, la imaginabilidad se mide a través de cuestionarios subjetivos en los que los participantes tienen que puntuar sobre una escala, generalmente entre los valores 1 y 7, la facilidad para imaginarse el significado de una palabra.
La imaginabilidad está estrechamente relacionada con la variable concreción/abstracción, dado que los objetos concretos son fáciles de imaginar y los abstractos difíciles de imaginar. Un problema con la variable imaginabilidad es que, al ser cuantificada mediante escalas subjetivas, puede ser afectada por otras variables relacionadas y que los sujetos no pueden separar, por ejemplo, la familiaridad o la frecuencia.
Polisemia
Aunque se han obtenido resultados contradictorios, la mayoría de ellos indican que las palabras que tienen mayor número de significados se reconocen más rápido que las que tienen pocos significados, especialmente cuando se trata de palabras de baja frecuencia (Cuetos, Domínguez y de Vega, 1997; Jastzrembski, 1981). Los efectos de polisemia son más acusados cuanta mayor implicación semántica exija la tarea, es también importante que todos los significados de la palabra vayan en la misma dirección (polisemia), pues cuando los significados son distintos (homografía) los resultados no son tan claros.
Morfología
Esta cuestión ha generado muchos estudios, especialmente en castellano, al tratarse de una lengua de una gran riqueza morfológica, en comparación con la relativa pobreza del inglés. Esto ha proporcionado a los investigadores en lengua castellana posibilidades de estudio vedadas a los investigadores anglosajones. Por ejemplo, el procesamiento de los afijos de género de los nombres y adjetivos o el del modo subjuntivo de los verbos en castellano, ambos características inexistentes en inglés. Se han propuesto dos hipótesis alternativas sobre el reconocimiento de las palabras morfológicamente complejas:
- La hipótesis del listado exhaustivo sostiene que cada palabra compuesta tiene su propia representación léxica independiente. Según esta hipótesis, la frecuencia de cada palabra es la que determina los tiempos de reconocimiento.
- La hipótesis de la segmentación obligatoria, en cambio, mantiene que las palabras son segmentadas en sus morfemas componentes, por lo que se accede a la raíz y a los afijos de manera independiente.
Por lo tanto, lo que determina el reconocimiento es la frecuencia de la raíz y de los afijos correspondientes.
Contenido emocional
El contenido emocional de las palabras también influye en su procesamiento. Un caso particular relacionado con el contenido emocional de las palabras lo constituyen las denominadas palabras tabú. Parece que las palabras tabú «absorben recursos de procesamiento»; la discusión se centra en si este fenómeno es automático e inevitable o se halla bajo control voluntario.
| Wurm, Vakoch y Seaman (2004). A igualdad de otras condiciones, los tiempos de reacción son más rápidos para las palabras con alta carga en determinadas dimensiones emocionales. |
| MacKay et al. (2004). Desde hace tiempo se sabe que las palabras tabú no se procesan igual que las otras palabras y que se recuerdan mejor en pruebas de memoria y, además, deterioran el recuerdo de la palabra precedente y posterior dentro de una lista. |
MODELO DE RECONOCIMIENTO DE PALABRAS
¿Por qué un modelo? La ciencia recurre a teorías y modelos teóricos para avanzar y entender mejor lo que nos rodea. Un modelo pretende ser una construcción teórica que representa cierta realidad de difícil manejo u observación directa. Necesitamos modelos para entender aspectos de la realidad que escapan a nuestra intuición. Un modelo ofrece una visión unificadora sobre fenómenos dispersos cuya conexión no es evidente a primera vista. Los modelos no se construyen en el vacío, sino que parten de datos de la realidad, pero, al proporcionar una visión más completa del fenómeno, son fuente de nuevas hipótesis que deben ser verificadas otra vez de forma empírica. Es un camino de ida y vuelta entre el modelo y el fenómeno real. De esta manera, los modelos tienen capacidad predictiva.
El principio de falsabilidad de Karl Popper establece que una buena teoría debe ser falsable, refutable por los datos. Una teoría psicológica (p. ej., el psicoanálisis) que intente explicarlo todo a posterior a una cosa y también su contraria, que no plantee a priori hipótesis específicas empíricamente verificables, ayuda poco al avance acumulativo de la ciencia y no permite superar los argumentos circulares meramente especulativos. Muchos modelos científicos se basan en una analogía que les abre nuevas oportunidades. Los procesos mentales pertenecen a un dominio muy resbaladizo que el físico, dada la enorme cantidad de variables intervinientes no controladas, pero la analogía del ordenador y el procesamiento de la información ha sido útil durante cuatro décadas. Hoy muchos autores apuntan hacia la analogía del propio cerebro: su microestructura debe servir de guía, hay que caminar hacia modelos de estructuras reticulares altamente interconectadas. En el campo específico de la psicolingüística, la analogía del diccionario mental ha tenido una poderosa influencia en la investigación sobre el procesamiento de las palabras.
La psicolingüística, como la psicología cognitiva en general, es una disciplina científica en la que apenas existen áreas con un modelo único admitido por todos. Por el contrario, es normal que varios modelos alternativos compitan por explicar mejor los subprocesos modelados, y la evidencia empírica tiende a repartirse entre ellos. La realidad mental es bastante escurridiza y muchas veces juega al gato y al ratón con los investigadores; se resiste a mostrar regularidades sencillas fácilmente “capturable”. En ocasiones, pequeñas variaciones en las condiciones experimentales conducen a resultados contradictorios. Una situación habitual es que originalmente un modelo surge con una estructura relativamente simple y parsimoniosa, elegante en términos científicos, y, sin embargo, la necesidad de explicar nuevos resultados que no encajan bien obliga después a complicar el modelo.
Los modelos del acceso léxico se dividen fundamentalmente entre los que defienden un acceso directo al léxico mental (p. ej., modelo del logogén) y los que consideran la existencia de algún tipo de mecanismo de búsqueda serial (modelo de Forster). El modelo de cohorte de Marslen-Wison se califica de híbrido en este sentido. Sin olvidarnos de los los modelos conexionistas (TRACE).
Modelos de acceso directo: modelo del logogén
| Morton (1969). Desarrolla el modelo Logogén original. |
| Winnick y Daniel (1970). Demostraron que la lectura en voz alta de una palabra facilitaba su reconocimiento taquistoscópico posterior, pero nombrar una palabra ante un dibujo, o producirla en respuesta a una definición, no influye luego en su reconocimiento taquistoscópico. |
| Coltheart, Davelaar, Jonasson y Besner (1977). Sugirieron la existencia de un tiempo límite para reconocer las palabras en el sistema de logogenes. Una vez agotado este plazo sin que se haya disparado ningún logogén, se rechaza el estímulo como no-palabra. |
| Morton, Petterson (1980). Desarrollan una versión mejorada del modelo Logogén original. |
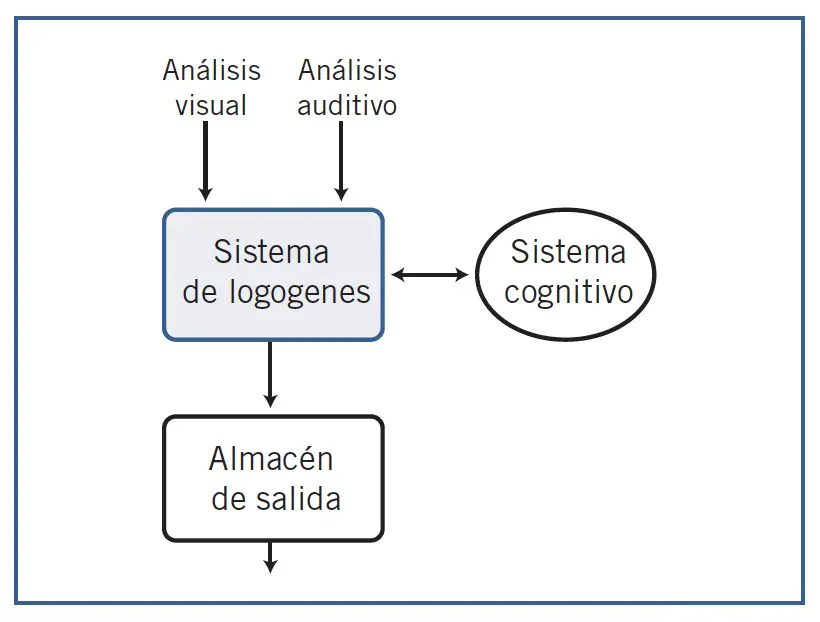
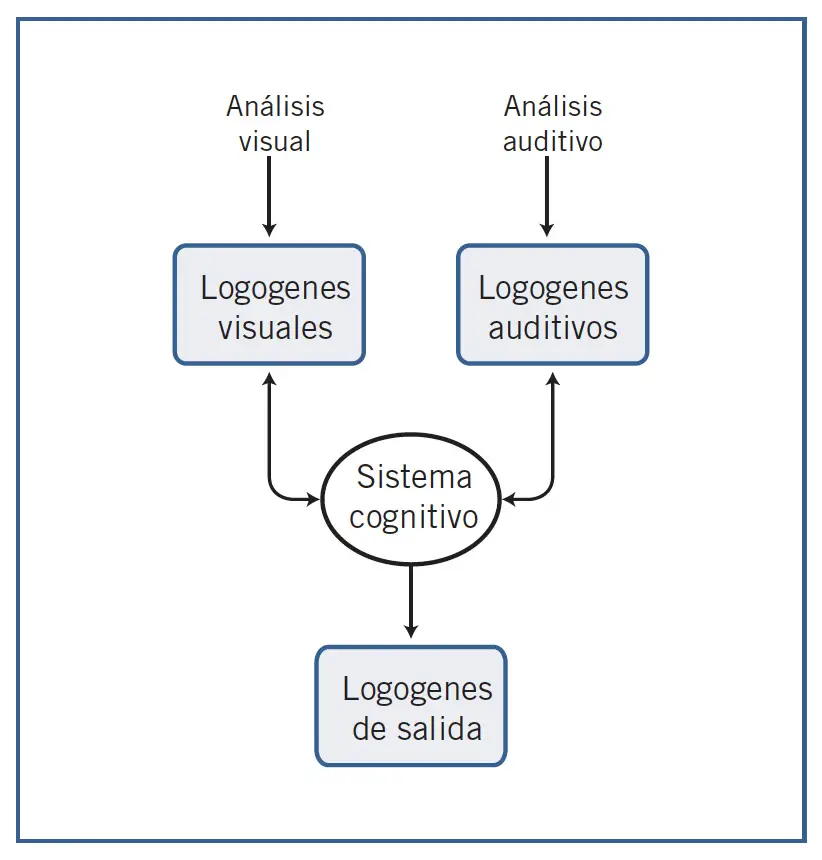
En 1968 John Morton planteó un modelo que ha sido muy influyente en la investigación sobre el reconocimiento de las palabras. De acuerdo con la formulación original del modelo, al sistema de logogenes llega información en paralelo desde tres fuentes distintas: representaciones ortográficas obtenidas por el análisis visual de las palabras escritas, representaciones auditivas de las palabras habladas, y representaciones semánticas procedentes del sistema cognitivo. Las dos primeras son fuentes externas al sujeto porque corresponden a la información de entrada del estímulo, mientras que la tercera es información interna que procede de su propio sistema cognitivo. Esta última es la que utilizamos en la producción del lenguaje, al nombrar dibujos u objetos, o cuando pensamos en las palabras que vamos a emplear.
Ahora bien, el sistema de logogenes no hace distinción entre las fuentes, y para él las tres son externas. Una vez que la información ingresa en el sistema de logogenes, ésta tiene el mismo valor funcional independientemente de cuál ha sido su origen, todas son funcionalmente equivalentes. De este modo, Morton explica el efecto del contexto: en la medida en que los logogenes disponen de mayor información procedente del sistema cognitivo, es decir, la denominada información arriba-abajo proveniente de los procesos superiores, necesitará menos información sobre el estímulo (de abajo-arriba) para la identificación de las palabras. Se trata de un modelo interactivo, porque la información contextual ejerce su influencia desde el primer momento en el proceso de reconocimiento de palabras.
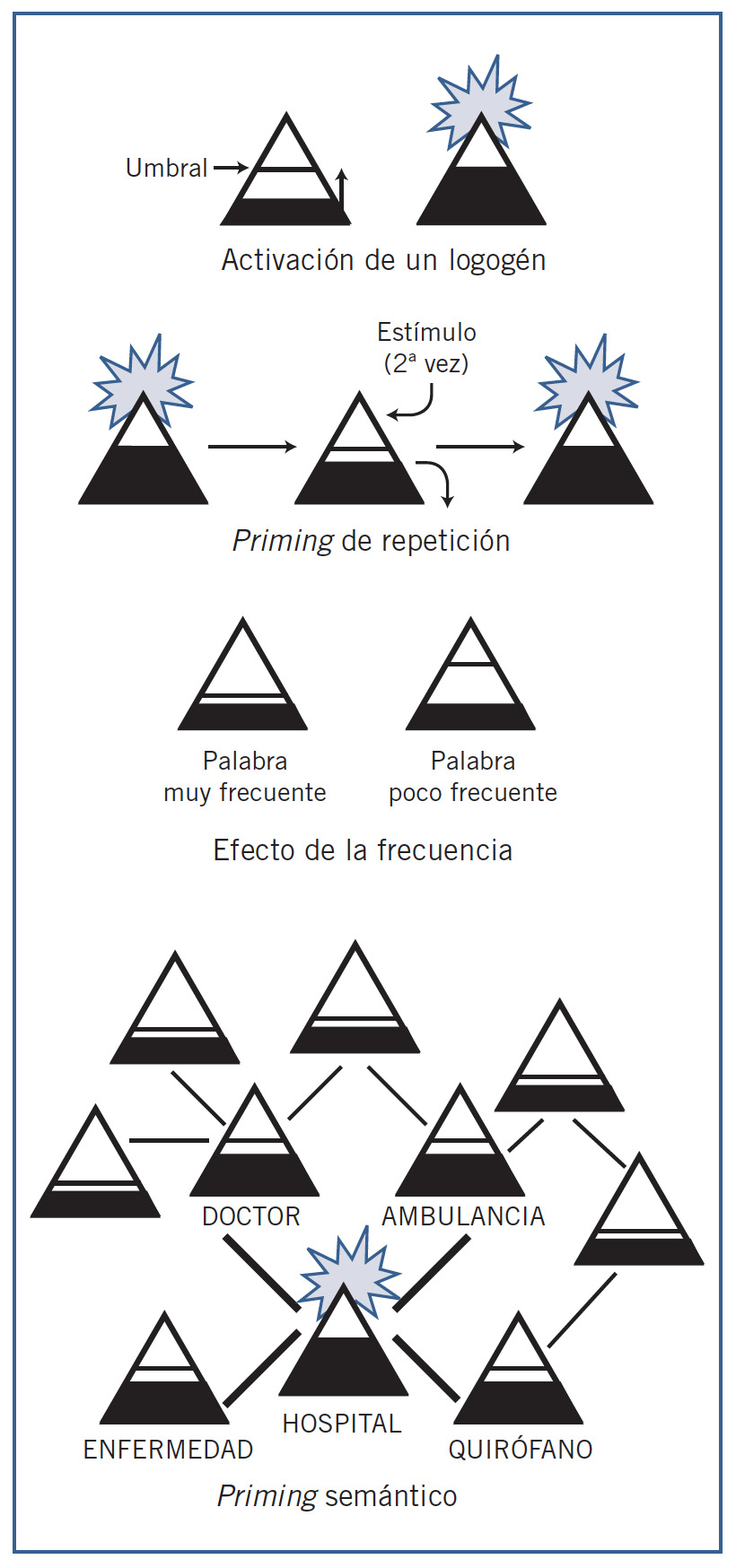
Después de que un logogén ha sido activado al identificar una palabra, su activación desciende al nivel de reposo, pero esto no ocurre de forma instantánea, sino que lleva cierto tiempo. Por lo tanto, las palabras recién activadas retendrán una activación residual superior a la de reposo durante un corto período de tiempo; si en ese momento el estímulo de entrada vuelve a activar el mismo logogén, éste se disparará antes, reconociendo de nuevo la palabra con mayor facilidad. Es así como se explica el priming de repetición. Morton propone que cada logogén tiene un umbral de disparo distinto. Las palabras de alta frecuencia, que son familiares al sistema de logogenes porque se han presentado muchas veces a lo largo de la vida del sujeto, cuentan con logogenes con un umbral más bajo. Por eso se activarán antes que las palabras poco frecuentes, que tienen umbrales más altos y necesitan mayor cantidad de activación antes de alcanzarlo. Así es como el modelo explica el efecto de la frecuencia léxica. Por otra parte, los logogenes están conectados entre sí de manera que se comunican la activación, y ésta se extiende entre los logogenes cercanos, si bien este proceso tampoco sucede de forma instantánea. Las palabras semánticamente próximas, con significados similares, tienen logo-genes cercanos entre sí y con mayor probabilidad de comunicar sus respectivas activaciones. De este modo, Morton explica el efecto del priming semántico. Cuando, por ejemplo, leemos la palabra «hospital», se activa su logogén, y parte de su activación se comunica a los logogenes próximos, como «doctor», «enfermedad», «ambulancia», «quirófano», etc. Si en ese momento entra información congruente con la palabra «doctor», su logogén se disparará antes gracias a la activación recibida desde el logogén «hospital».
Morton no pudo mantener la sencillez de su esquema original porque no era capaz de explicar algunos datos experimentales que iban apareciendo. El modelo opera únicamente con unidades léxicas, por lo que no está claro cómo se procesan las unidades subléxicas, como las sílabas y otras. El modelo postula que debería existir una facilitación clara entre modalidades sensoriales distintas, o priming transmodal de repetición, que no es confirmada por los datos. Tampoco se observa facilitación desde el canal cognitivo; Winnick y Daniel (1970) demostraron que la lectura en voz alta de una palabra facilitaba su reconocimiento taquistoscópico posterior, pero nombrar una palabra ante un dibujo, o producirla en respuesta a una definición, no influye luego en su reconocimiento taquistoscópico.
Morton y Patterson desarrollan una nueva versión del modelo Logogén original. En lugar de uno, se consideran tres sistemas distintos de logogenes: uno por cada modalidad sensorial o canal de entrada (visual frente a auditiva), más un tercer sistema de salida. De este modo, los sistemas se mantienen separados sin influencias entre modalidades. Evidencia experimental posterior sugirió la necesidad de considerar cuatro sistemas: uno para leer, otro para escribir, otro para escuchar y otro para hablar. A la luz de los datos experimentales que han ido apareciendo durante las últimas décadas, han surgido nuevas versiones y variantes del modelo del logogén.
Modelos de búsqueda serial: modelo de Forster
| Kenneth Forster (1976). Modelo de búsqueda serial de Foster. |
| Becker (1979). Modelo de verificación de Becker. Pretende, entre otras cosas, dar una explicación más sofisticada del priming semántico. |
| Glanzer y Ehrenreich (1979). Modelo de búsqueda serial del diccionario de bolsillo. Plantea que hay a nuestra disposición dos diccionarios mentales: uno que contiene información de todas las palabras, y otro que contiene información sólo de las palabras muy comunes, de alta frecuencia, a modo de una especie de diccionario de bolsillo. Estos autores defienden que el efecto de la frecuencia se debe al uso de uno u otro diccionario, pero, dentro de un diccionario, el tiempo de búsqueda no varía con la frecuencia léxica. |
| Kenneth Forster (1989). Revisión del modelo de búsqueda serial de Foster, en esta versión, asume diferentes niveles de actividad para las entradas en los ficheros de acceso, para explicar el priming basado en las similitudes ortográficas entre los estímulos. |
| Kenneth Forster (1994). Nueva revisión del modelo de búsqueda serial de Foster, en esta versión, incorpora un rasgo de paralelismo sugiriendo que, dentro de cada fichero de acceso, se produce una búsqueda simultánea en todos sus bins. |
| Harley (2001). Otro de los puntos débiles del modelo de búsqueda serial de Foster ha sido la incapacidad para explicar convincentemente cómo se pronuncian y procesan las no-palabras . |
Los modelos de búsqueda serial conciben mecanismos semejantes al de identificar una palabra en un diccionario convencional. Se explora a través de las entradas léxicas, que están ordenadas para facilitar la búsqueda, y, una vez localizada la palabra, el diccionario proporciona toda la información almacenada sobre ella. El modelo más conocido de este tipo es el propuesto por Kenneth Forster (Forster, 1976, 1979). El modelo plantea una búsqueda en dos etapas; la primera se llevaría a cabo a través de ficheros de acceso, y la segunda en un gran archivo maestro o principal. La primera fase ocurre en uno de tres posibles ficheros de acceso, específicos de una modalidad de información. Uno contiene la información ortográfica de las palabras, o fichero de acceso ortográfico para las palabras escritas; otro contiene información acústica y fonológica de las palabras habladas, o fichero de acceso fonológico, y el tercero almacena información sintáctica y semántica de las palabras y se usa en la producción de lenguaje.
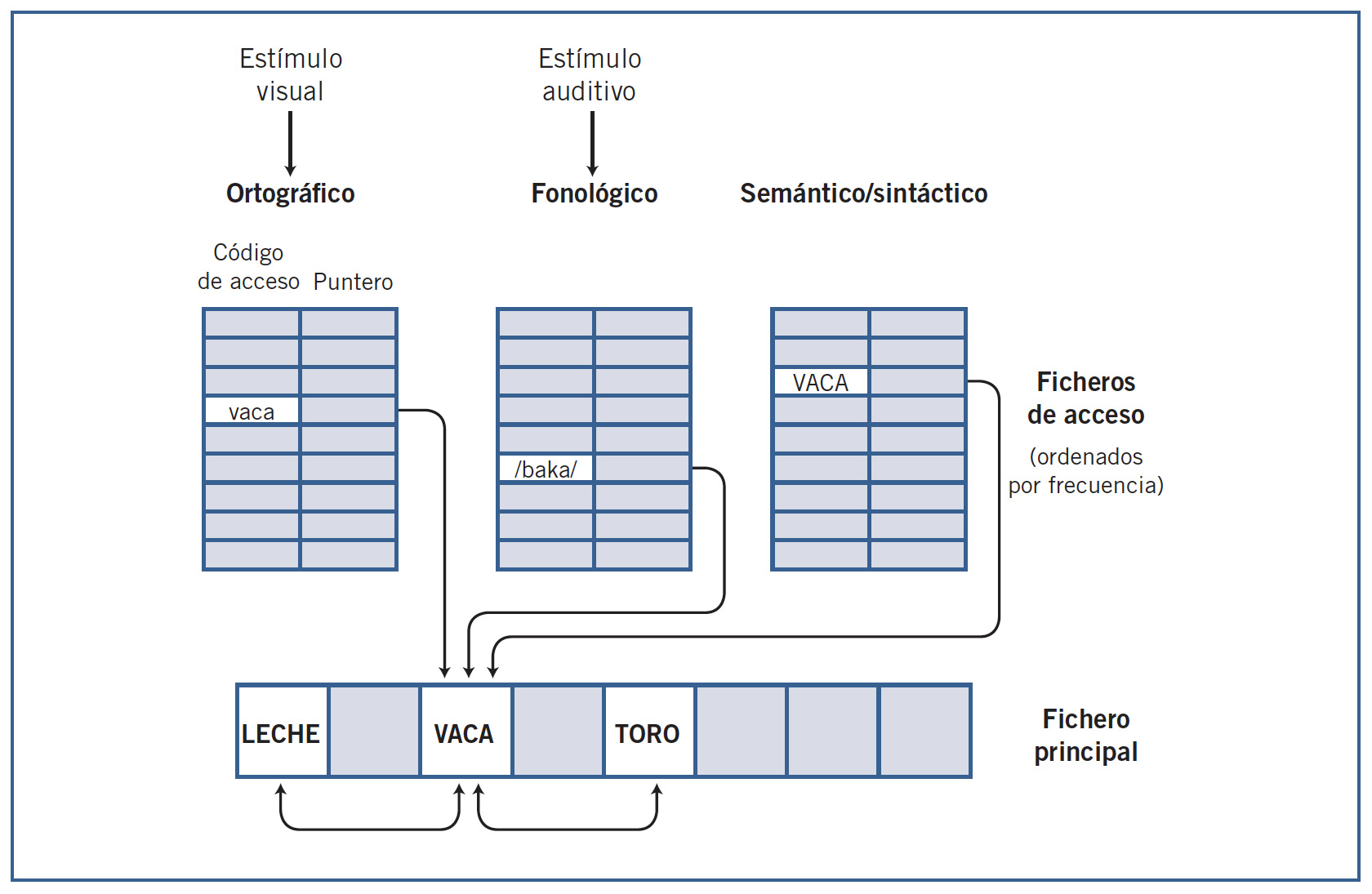
Se trata de un modelo de tipo modular porque la información de los niveles lingüísticos superiores (oracional y supraoracional) no incide directamente en el proceso de acceso o localización de las palabras. El único efecto de contexto que puede darse es a través de las referencias cruzadas dentro del fichero maestro y así es como se explica el priming semántico. No hay lugar para un efecto temprano del contexto de la frase que pudiera operar sobre el acceso léxico. Los efectos de contexto actuarían a través de mecanismos posteriores, o de tipo postacceso. El priming de repetición ocurre porque puede haber un cambio temporal en el orden de los ítems dentro de cada bin, debido a su uso. Las no-palabras se rechazan una vez que ha habido una búsqueda exhaustiva en el bin correspondiente, lo cual en general consume más tiempo que la localización de una palabra.
El modelo de Forster y el planteamiento de un mecanismo de búsqueda serial ha tenido, y tiene, gran influencia en la comunidad psicolingüística. Sin embargo, las críticas más importantes se dirigen, precisamente, a ese mecanismo serial, que no todos admiten. El modelo da cuenta de los principales datos experimentales y predice que los efectos de priming están limitados al priming semántico dentro del archivo principal, sin que, como se ha mencionado, el reconocimiento de palabras se vea influido por información de tipo arriba-abajo procedente de niveles superiores de procesamiento (frase). Otro de sus puntos débiles ha sido la incapacidad para explicar convincentemente cómo se pronuncian y procesan las no-palabras.
Modelos mixtos: modelo de cohorte
| Marslen-Wilson y Welsh, (1978). En tareas de corrección de errores, una variante del sombreado donde los oyentes deben repetir correctamente palabras que tienen algún fonema cambiado (p. ej., repetir «tragedia» al oír «travedia»), esos errores se corrigen mejor cuando aparecen en la primera sílaba, que cuando surgen en la tercera. |
| Marslen-Wilson (1987; Marslen-Wilson y Tyler, 1980). Modelo de cohorte de Marslen-Wilson. supone una solución mixta entre los modelos de acceso directo y los de búsqueda serial. |
| Allopena, Magnuson y Tanenhaus (1998). Los datos demuestran que cuando se oye la palabra beaker (cubeta, vaso de laboratorio), también se activa speaker (hablante). |
| Jusczyk y Luce (2002). La versión más temprana de la teoría de cohorte presagiaba muchos de los temas de los que se habría de ocupar la investigación sobre el reconocimiento de las palabras habladas en los años venideros. De hecho, muchas cuestiones que dominan actualmente la investigación en este campo tienen sus raíces en ella. |
El modelo de cohorte supone una solución mixta entre los modelos de acceso directo y los de búsqueda serial. Lo es en la medida en que postula una secuencia ordenada de etapas, pero en ellas se activan paralela y simultáneamente varios elementos léxicos. Se trata de un modelo concebido únicamente para las palabras habladas.
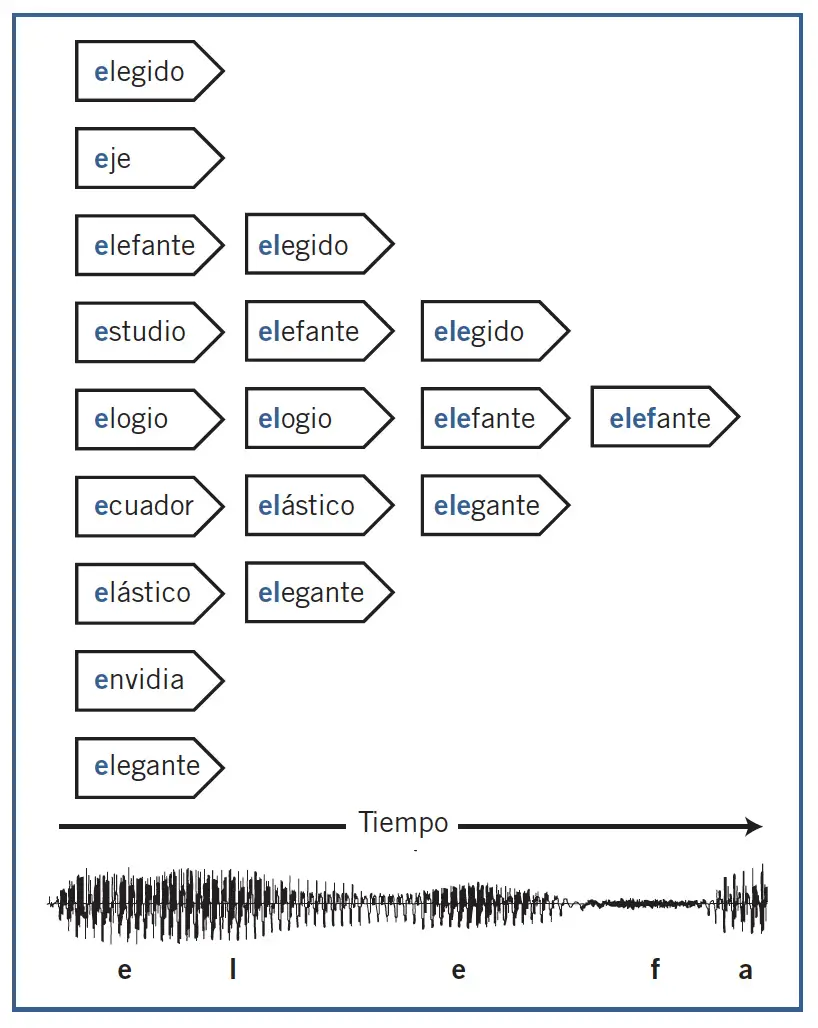
El modelo plantea lo siguiente: mientras una persona está escuchando una palabra (p. ej., «elefante»), desde el principio se activan en paralelo un conjunto finito, o «cohorte», de palabras congruentes con los sonidos iniciales, y todas ellas serían inicialmente candidatos léxicos del estímulo. Son representaciones que compiten en el proceso de identificación. Así, al oír la vocal inicial de «elefante» se activarían palabras que empiezan por esa vocal, como «estudio», «ecuador», «elegido», «elefante», etc. A medida que el estímulo va ingresando en el sistema perceptivo, la cohorte inicial se reduce y se van desactivando los candidatos incompatibles con la secuencia de sonidos. Al final sólo queda activo el único candidato coherente («elefante») con esa particular secuencia acústica. El modelo plantea que cada palabra tiene un punto de unicidad, o punto óptimo de reconocimiento, a partir del cual la palabra queda como candidato único y es reconocida sin esperar al final (p. ej., «elefante» tendría su punto de unicidad después de la secuencia «elef»).
Los resultados sugirieron a Marslen-Wilson que la percepción de una palabra se basa en un continuo estrechamiento del abanico de candidatos posibles hasta alcanzar el punto de unicidad, momento en que se produciría la identificación léxica. Ese punto es diferente para cada palabra, dado que depende de los otros candidatos. Aquí, la información del contexto puede influir acelerando el proceso mediante la eliminación de competidores de la cohorte que son poco congruentes con ese contexto. Compartir la porción inicial de las palabras no es una condición indispensable para que se activen los competidores.
Pese a su enorme impacto teórico, el modelo de cohorte no explica convincentemente algunos efectos empíricos. Dos son sus principales debilidades.
- Por una parte, cualquier mínima discrepancia del estímulo en sus partes iniciales lo excluiría inmediatamente de la cohorte y su representación no podría ser activada e identificada.
- El segundo punto débil es que no explica bien el efecto de la frecuencia léxica. ¿Por qué cuando dos palabras comparten la misma porción inicial hasta el punto de unicidad, como «puer/ta» y «puer/to» (ejemplo de Belinchón et al., 1992), se identifica antes la palabra más frecuente («puerta») que la menos frecuente («puerto»).
Modelos conexionistas: TRACE
| McClelland y Elman (1986). Modelo TRACE. Se trata de un modelo para el reconocimiento de las palabras habladas, derivado de un modelo anterior sobre las palabras escritas desarrollamdo por McClelland y Rumelhart en1981. |
Se trata de un modelo conexionista formado por múltiples unidades simples conectadas entre sí.
Estas unidades están organizadas en tres niveles de procesamiento. En la parte inferior, un primer nivel correspondiente a las unidades de entrada se encarga de analizar el input, o estímulo entrante, en sus rasgos fonológicos elementales, como sonidos sordos, sonoros, difusos, agudos, etc. Este nivel está conectado con el siguiente, que representa a los fonemas. Finalmente, el nivel de los fonemas se conecta con el nivel superior correspondiente a las palabras.
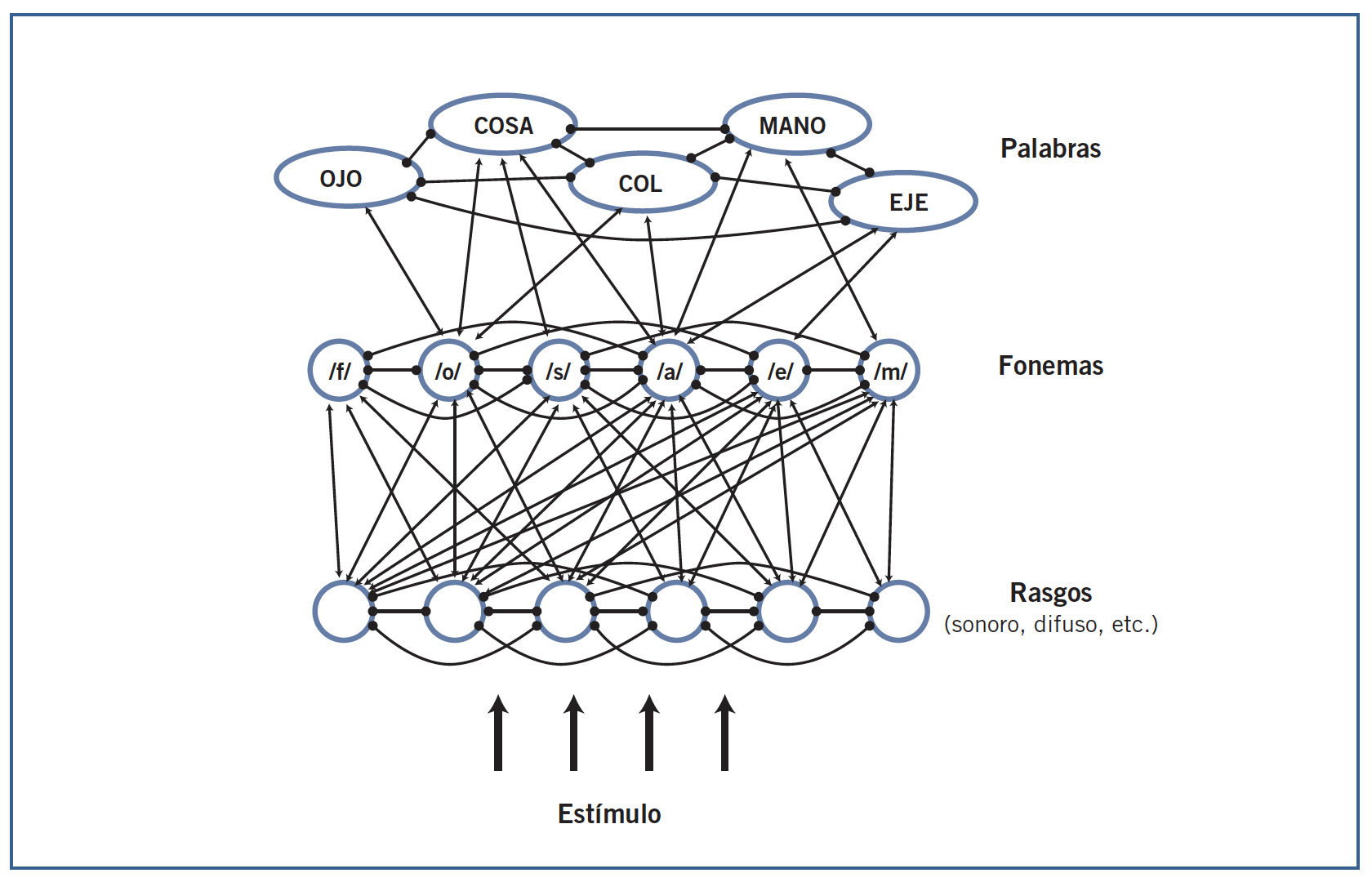
En este esquema general, la información fluye desde abajo hacia arriba, pero, al mismo tiempo, los niveles superiores influyen sobre los inferiores, facilitándoles la tarea. Precisamente, la característica más importante de TRACE es que concede gran importancia a los procesos de arriba-abajo (top-down), de manera que el nivel de las palabras actúa sobre el nivel de los fonemas, y éste sobre el de los rasgos fonológicos.
Una de sus ventajas consiste en que puede ser implementado matemáticamente en computadores para llevar a cabo simulaciones cuyos resultados pueden contrastarse con los obtenidos experimentalmente en seres humanos. El modelo explica bastante bien los efectos del contexto léxico y fenómenos asociados, como la restauración fonémica y la coarticulación. Localiza apropiadamente los límites entre las palabras dentro de una cadena hablada y funciona correctamente con estímulos ruidosos, semejantes a los que se dan en condiciones naturales. No obstante, TRACE tampoco está exento de problemas. Uno de sus inconvenientes reside en su propia flexibilidad: son muchos los parámetros que pueden ser manipulados en TRACE, pero los que se acomodan a unos resultados no son con frecuencia los mismos que se ajustan a otros resultados distintos. Por otra parte, la manera en que trata el tiempo en el estímulo de entrada, segmentándolo en cortes iguales, no parece muy realista.
BASES NEUROLÓGICAS
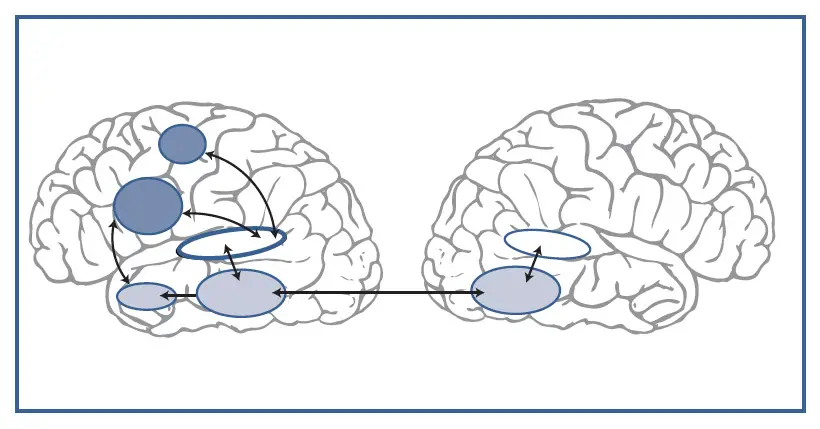
La primera hipótesis planteaba que el lenguaje oral se percibía mediante la corteza auditiva, ya que los pacientes que presentaban dificultades graves de comprensión (afasia de Wernicke) sufrían lesiones en la circunvolución temporal superior del hemisferio izquierdo. Este planteamiento inicial se ha visto desafiado por dos descubrimientos importantes (Hickok y Poeppel, 2007). El primero es que algunos trastornos en la capacidad de procesar sonidos del lenguaje guardan poca relación con las dificultades de compresión observadas en la afasia de Wernicke. El segundo es que la destrucción de la circunvolución temporal superior izquierda puede coexistir con una comprensión normal y, por el contrario, con problemas en la producción oral. Sabemos que la circunvolución transversa de Heschl, que corresponde al área auditiva primaria, en la parte superior de ambos lóbulos temporales, interviene directamente en el primer procesamiento de toda clase de sonidos, sean lingüísticos o no.
Hickok y Poeppel (2004, 2007) plantean en su modelo que la entrada sensorial auditiva es procesada a través de dos grandes sistemas o rutas neurales (streams):
- Sistema o ruta ventral («qué»). La ruta ventral procesa la señal de habla para su comprensión. Se considera que la ruta ventral es bilateral, aunque con importantes diferencias computacionales entre ambos hemisferios cerebrales.
- Pone en contacto el sonido con el significado, la información de la señal acústica con las representaciones semánticas y conceptuales del lenguaje.
- Este sistema o conjunto de redes ventrales abarca áreas de la parte media e inferior de ambos lóbulos temporales los cuales, a su vez, están interconectados entre sí a través de las fibras del cuerpo calloso y estructuras subcorticales.
- El sistema involucra múltiples niveles de procesamiento que actúan sobre distintos niveles de representación:
- Rasgos distintivos.
- Segmentos fonéticos.
- Estructuras silábicas.
- Formas fonológicas de las palabras.
- Rasgos gramaticales.
- Información semántica.
- No está claro si la computación del habla implica obligatoriamente a todos estos niveles de procesamiento operando de forma serial y jerárquica o actúan en paralelo y con cierto grado de flexibilidad según los requerimientos de la tarea.
- El hecho de que el sistema ventral sea bilateral explica por qué es posible encontrar pacientes con lesiones en las estructuras del hemisferio izquierdo que no presenten serias dificultades de compresión oral, mientras que las lesiones bilaterales sí las causan.
- Dentro del sistema ventral se dan ciertas diferencias computacionales entre los dos hemisferios que afectan sobre todo a la escala temporal de integración.
- El hemisferio derecho mostraría selectividad para actuar en una escala amplia de 150-300 ms, propia de la información suprasegmental (prosodia o entonación) del habla.
- El hemisferio izquierdo parece menos selectivo y podría actuar tanto en esa escala de integración, como en una escala más corta de 20-50 ms, en lo que sería un procesamiento rápido propio del nivel segmental.
- La porción anterior o delantera del lóbulo temporal desempeña un papel relevante en el procesamiento semántico del habla, sobre todo al nivel de oración. Los experimentos basados en las técnicas de neuroimagen funcional presentan a esta área selectivamente activada cuando los participantes escuchan palabras organizadas en frases, frente a listas no estructuradas de palabras.
- El efecto del material estructurado frente al no-estructurado puede ocurrir incluso en ausencia de contenido semántico, aunque sí es sensible a manipulaciones experimentales de carácter semántico.
- Sistema o ruta dorsal («dónde»). La ruta dorsal proyecta la información sobre las redes articulatorias del lóbulo frontal izquierdo.
- Está fuertemente lateralizada en el hemisferio izquierdo dominante.
- Esta ruta actuaría de interface con el sistema motor del lóbulo frontal izquierdo.
- Esta ruta corresponde a las redes articulatorias y tendría un papel esencial en la integración auditivomotora.
- Destacan la importancia de las primeras etapas de desarrollo del habla:
- Aprender a hablar es esencialmente una tarea de aprendizaje motor guiada por un feedback auditivo
- Se construyen las piezas básicas o patrones neuromotores que luego intervendrán en el lenguaje hablado.
- Hay evidencia del efecto disruptivo que en la edad adulta ejerce sobre la producción del habla la alteración experimental del feedback auditivo, así como las consecuencias en la articulación causadas por una sordera de aparición tardía.
- Los autores sugieren que existen al menos dos niveles de interacción auditivomotora:
- Uno estrecho que implicaría segmentos fonéticos.
- Otro más amplio, que abarcaría secuencias de segmentos y que intervendría principalmente en la adquisición de nuevo vocabulario.
- En la medida en que las palabras se hacen más familiares en su uso, este último nivel de integración se volvería más automático y agruparía secuencias motoras más amplias.
- Las lesiones unilaterales en el sistema dorsal causan con frecuencia dificultades en la producción del habla.
- Afasia de conducción, en la que el daño se localiza preferentemente en la unión temporoparietal o en las fibras del fascículo arqueado, que forma parte de la ruta dorsal. Este síndrome de desconexión se caracteriza generalmente por una buena comprensión oral, pero presenta frecuentes errores fonémicos en la producción verbal. Estos síntomas son sensibles a la carga de procesamiento: los errores son más probables cuando se pronuncian palabras más largas, palabras menos frecuentes y con menos restricciones semánticas debidas al contexto.
Este modelo dual pretende integrar un gran volumen de observaciones empíricas que incluyen procesos perceptivos básicos, aspectos del desarrollo del habla, hechos neuropsicólogicos y psicolingüísticos, y la evidencia más reciente aportada por las técnicas de electrofisiología y neuroimagen funcional. El concepto básico de que la información sensorial debe ser procesada por dos sistemas diferenciados, uno conceptual o del significado, y otro articulatorio-motor, se ajusta bien a un marco dual también planteado para el dominio visual y más recientemente para el somatosensorial.
AUTOEVALUACIÓN
ENLACES DE INTERES
- Demostración de priming enmascarado (en inglés). http://www.u.arizona.edu/~kforster/priming/
- EsPal: Base de palabras en castellano para búsquedas según variables psicolingüísticas. http://www.bcbl.eu/databases/espal/
REFERENCIAS
- Cuetos Vega, González Álvarez, Vega, and Vega, Manuel De. Psicología Del Lenguaje. 2ª Edición. ed. Madrid: Editorial Médica Panamericana, 2020.
- PDF Profesor tutor Pedro R. Montoro
- YouTube
- Resumen Mª José Ramos